В любых решениях в области кибернетической безопасности, в частности при создании систем мониторинга информационного пространства, необходимо научное обоснование применения технологий и решений. Не исключения и системы мониторинга открытых источников, включая веб-сайты и социальные сети. Сервис мониторинга, прогнозирования и автоматизированного определения информационных угроз attackindex.com создала команда, состоящая из представителей технических и компьютерных наук, прикладной математики, медиа, социологии, ИТ и информационной безопасности. Именно поэтому все современные научные достижения, в первую очередь собственные, получают скорую имплементацию к сервису Атак Индекс.
Искусственный интеллект это стек (совокупность) технологий, включающих машинное обучение, нейронные сети, распознавание образов. Элементы этих технологий применяются в Атаке Индексе. В частности:
• Машинная учеба – тональность сообщений, рейтингование источников, прогнозирование развития информационных динамик;
• Кластерный анализ – автоматизированная группировка текстовых сообщений, обнаружение сюжетов, формирование сюжетных цепочек;
• Компьютерная лингвистика – выявление постоянных словосочетаний и нарративов;
• Формирование, кластеризация и визуализация семантических сетей – определение связей и узлов, развитие когнитивных карт;
• Корреляционный и вейвлетный анализ – выявление информационных операций.
Благодаря применению приведенных технологий, Атак Индекс позволяет фиксировать и отслеживать информационные процессы, формирует систему аналитических показателей, определяет стабильность информационных ситуаций и прогнозирует их развитие. Автоматизированный отчет Атак Индекса сохраняет время и повышает эффективность работы аналитиков, в частности – в формировании сюжетов по темам исследований для понимания контекста и трендов на больших промежутках времени. Базы данных Атак Индекса доступны для обработки любых запросов на больших временных сроках и позволяют получать информационные динамики – то есть количество найденных упоминаний ключевых слов запроса на каждую дату запроса.
С помощью стандартных возможностей офисных пакетов статистические ряды, в частности, информационные динамики, могут быть обработаны для поиска взаимосвязей между ними. Исследование взаимосвязей выполняется с помощью расчетов коэффициентов корреляции для одинаковых временных интервалов, также производятся расчеты коэффициентов корреляций в условиях смещения одного относительно другого.
Большие Данные
Только в 2014 году Google проиндексировала 60 триллионов документов в интернете, а c 2016 по 2025 год IDC прогнозирует десятикратный рост количества данных, до 163 зеттабайт. А по прогнозам компании Cisco в 2021 году в секунду будет передаваться более 100 000 ГБ данных. В 2016 эта цифра составляла почти 27 000 ГБ в секунду.
В случае множества информационных потоков, которые образуются отдельными тематическими информационными потоками, необходимо учитывать динамику каждого из них в отдельности. В случае изучения общего информационного потока часто наблюдается «перетекание» публикаций из одних, которые теряют актуальность, в другие.
Общая же тенденция изменений в исследуемой череде событий называется трендом. Весьма популярное сегодня слово также является и актуальным термином для изучения потоков публикаций. Потоки организованы набором сетевых информационных ресурсов и часто сопровождают информационные операции. Системой исследуются типовые тренды, свойственные потокам публикаций в сетевых информационных ресурсах, сопровождающих информационные операции.
Теория информации
Современное информационное пространство предоставляет уникальную возможность получения разнообразной информации по выбранному вопросу при наличии соответствующего инструментария, использование которого позволяет анализировать взаимосвязи возможных событий или событий, которые уже происходят, с информационной активностью выбранного круга источников.
Примеры сетей распространения информации, имеющих признаки информационных операций приведены на рисунке ниже. Такие шаблоны могут использоваться при распознавании образов, которые применяются к временным рядам и соответствующим объемам публикаций.
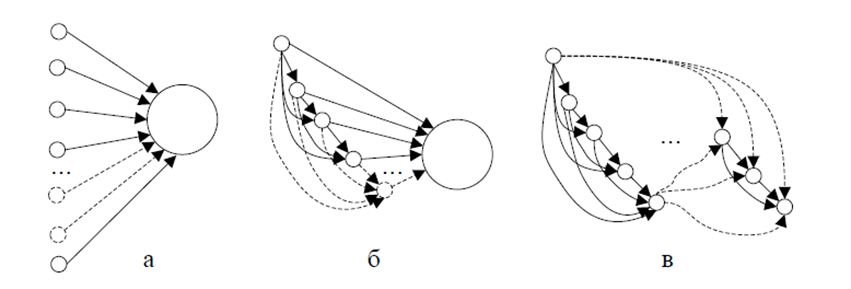
Приведенные схемы выше можно описать согласно теории распределения энергии. Каждая новая публикация появляется изначально с нулевым значением энергии. Затем, с ней могут происходить события, аналогичные социальным сетям — like, dislike, repost, share link. Условно, эти события влияют на энергию публикации следующим образом:
- like повышает энергию на 1;
- dislike уменьшает на 1;
- repost повышает на 2;
- share link повышает на 1.
Вероятность того, что какое-то из этих событий произойдет, зависит от актуальности сообщения, интереса к информации в нём. Все это в терминах такой теории выражается величиной энергии.
За единицу времени может произойти одно из этих событий, два одновременно или ни одного. Согласно таким правилам изменения энергии увеличение энергии на 2 соответствует тому, что произошли одновременно like и repost; увеличение на 1 – произошел только repost; энергия не меняется, если был like; dislike уменьшается на 1, если не произошло ни одного из событий.
Таким образом, публикации и их источники набирают вес в медиа пространстве. Они же влияют на то, чтобы конкретной информацией поделились пользователи, которые ориентируются на значимость публикации, определяемую именно по схеме которую мы описали.
Стартовое значение «энергии» публикации, можно набрать не только за счет «горячей» темы или актуальности. За нее как раз могут отвечать искусственные агенты влияния. После того как публикация наберет некую критическую массу (трехзначные счетчики комментариев и репостов, например), общество начнет органическое распространение заложенной в сообщении информации.
Управляемая информация
Информационная операция это информационное воздействие на массовое сознание (как враждебное, так и дружеское), воздействие на информацию, доступную объекту и необходимую ему для принятия решений, а также на информационно-аналитические системы конкурента. Любая информационная операция имеет следующие этапы:
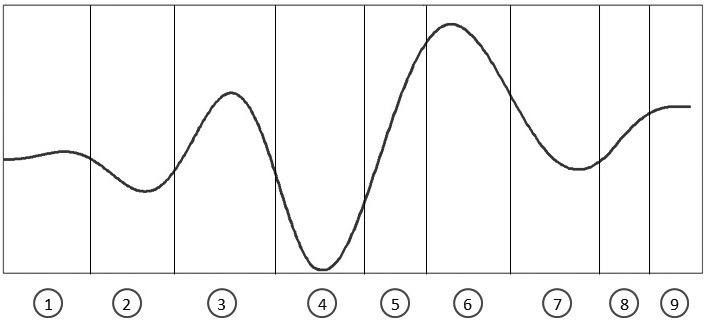
1 — фон; 2 — затишье; 3 — «артподготовка»; 4 — затишье; 5 — атака / триггер роста; 6 — пик завышенных ожиданий; 7 — потеря иллюзий; 8 — общественное осознание; 9 — производительность / фон
С другой стороны, при сборе и анализе информации возникают проблемы, когда речь идет о большом количестве данных, поиске и навигации в постоянно меняющихся информационных потоках. Стоит добавить и фактор многоязычности среди сайтов. Все это вызывает сложность использования упомянутых методов в информационно-аналитической работе.
Информационное пространство представляет собой динамическую систему из связанных по смыслу элементов (документов), образующихся в процессе своей эволюции информационные потоки.
Динамика публикации документов в информационном пространстве, в том числе, непосредственно относящиеся к информационным операциям, образуют временные ряды.
Методы анализа
Как раз к временным рядам можно применить формальные методы анализа: статистический, фрактальный, Фурье и вейвлет. Анализ этих потоков во времени позволяет выявить тенденции, циклы, аномалии и наличие корреляций.
При определении информационных операций, можно выделить три подхода:
- Базовые подходы, ориентированные на анализе тональности могут применяться лишь на этапах оперативного обнаружения;
- Подходы, ориентированные на анализ шаблонов могут использоваться при стратегическом анализе, планировании. Здесь скорее важно отклонение от обычных информационных всплесков и естественных шаблонов;
- Сетевые подходы хорошо совместимы с современными технологиями распознавания, нейронными сетями, однако не могут быть эффективными без «обучения», анализа информационных потоков за большие периоды времени.
На практике должны применяться гибридные подходы, учитывающие как машинное обучение, шаблоны, так и участие экспертов по знаниям. Поэтому для решения этих проблем в нашей системе применяются методы работы с Большими Данными (Big Data), машинное обучение, нейронные сети, текст-майнинг, а также привлекаются эксперты в исследуемых информационных областях.
Реализация методов
Attack Index – это интегральный показатель уровня информационной опасности, учитывающий множество факторов. В них входят: наличие информационной активности, активности возможных конкурентов, отклонение среднего фона, наличие информационных операций и стадий их развития, ретроспектива и динамика негативной тональности публикаций, а также степень хаотичности процессов. Кроме того, в разработке находится инструмент прогнозирования информационных событий.
Составляющие нашего решения:
- Поиск сообщений на темы, представляющие интерес в глобальных сетях;
- Отслеживание информационных потоков (историй), соответствующих тем, событий и процессов;
- Определение динамики информационных потоков;
- Построение динамики тональности публикаций;
- Определение аномального и критического момента в динамике тематических информационных потоков;
- Определение основных событий и объектов тематического потока информации;
- Визуализация отношений объектов мониторинга;
- Прогноз развития ситуации.
Изучение эмоций
Реализованная система определения тональности базируется на статистическом подходе и обучении нейронной сети. В основе статистики лежит выявление слов наиболее часто употребляемых в текстах с положительной или нейтральной тональностью.
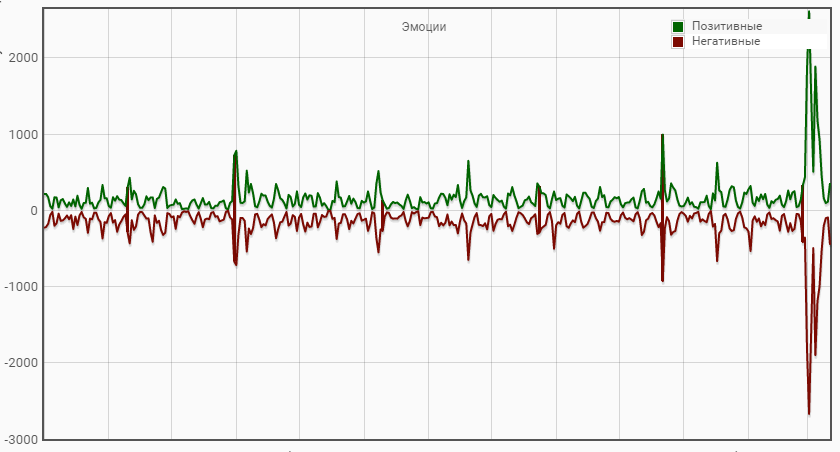
Следует помнить, что информационное пространство всегда больше реагирует на проблемные и негативные события. Как следствие, в информационных потоках, статистически, негатив встречается чаще. Даже эксперты не всегда приходят к согласию, что может быть негативом, а что – позитивом, поэтому задача системы правильно обработать найденные текстовые массивы и представить к рассмотрению оценочные значения.
Attack Index учитывает статистику отрицательных сообщений, динамику наращивания отрицательных тональностей, так как такие тенденции свидетельствуют о потенциально опасной ситуации относительно объекта запроса.
Участие в распространении
В список источников входят ведущие новостные сайты, региональные медиа, блоги и форумы. Но важным компонентом стали также сайты с сомнительной репутацией, ведь именно с них начинаются информационные волны. Источником большинства таких волнений являются и социальные сети: от имени профиля публикуется «горячая» информация, которая затем через поддержку не самых авторитетных сайтов транслируется и доходит до новостных служб и даже телеканалов. Такие проявления также учитываются при оценке ситуации.
С помощью методов выделения данных из текстов можно сформировать сети взаимосвязей понятий. Их узлы являются ключевыми словами, именами персоналий, компаниями и т.д. Анализ этих сетей позволяет выявить явные и неявные связи между отдельными понятиями, оценить вес тех или иных понятий, уточнить критерии формирования информационного потока и увидеть взаимозависимости в исследуемых сетях.
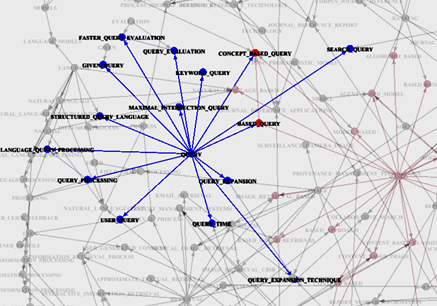
Важно понимать наличие и силу связей между агентами влияния и источниками. В нашем сервисе реализована технология автоматизированного формирования когнитивных карт на основе моделей предметных областей. Когнитивная карта — ориентированный граф, грани которого могут быть связаны с весом (энергией, как в примере выше).
Когнитивные карты могут использоваться для создания сценариев информационной поддержки. Вершины когнитивной карты соответствуют понятиям и причинно-следственным связям. При анализе когнитивных карт узлы и ссылки оцениваются относительно выбранной концепции, после чего между этими узлами образуются согласованные цепи.
Узлы могут быть связаны между собой, если соответствующие им слова находятся рядом в тексте, принадлежат одному предложению, соединенные синтаксически или семантически.

Научная литература, описывающая теорию и практику, использованные при создании сервиса Attack Index.
1.Ланде Д.В. Шнурко-Табакова Е.В. “ПЕРСПЕКТИВИ АВТОМАТИЗАЦІЇ АНАЛІТИЧНОЇ ДІЯЛЬНОСТІ У СФЕРІ НАЦІОНАЛЬНОЇ ОБОРОНИ І БЕЗПЕКИ”
2.Publication date. 2020/11/26. Conference Науково-практична конференція: “Забезпечення інформаційної безпеки держави у воєнній сфері: проблеми та шляхи їх вирішення”. Pages 89-90. Publisher. НАЦІОНАЛЬНИЙ УНІВЕРСИТЕТ ОБОРОНИ УКРАЇНИ імені Івана Черняховського
3.Ланде Д.В. Шнурко-Табакова Е.В. “МЕТОДИ І ЗАСОБИ АНАЛІТИЧНОЇ ПІДТРИМКИ ПРОТИДІЇ ГІБРИДНИМ ЗАГРОЗАМ ДЕРЖАВИ”
4.Publication date 2019/10/24. Conference. “ПРОБЛЕМИ ТЕОРІЇ ТА ПРАКТИКИ ІНФОРМАЦІЙНОГО ПРОТИБОРСТВА В УМОВАХ ВЕДЕННЯ ГІБРИДНИХ ВІЙН”. Pages 13-15. Publisher М-во оборони України, Житомир. військ. ін-т імені С. П. Корольова
5.Dmytro Lande, Ellina Shnurko-Tabakova. OSINT as a part of cyber defense system // Theoretical and Applied Cybersecurity, 2019. — N. 1. — pp. 103-108.
6.Горбулін В.П., Додонов О.Г., Ланде Д.В. “Інформаційні операції та безпека суспільства: загрози, протидія, моделювання: монографія”. Київ : Інтертехнологія, 2009. 164 с.
7.Dmytro Lande, Minglei Fu, Wen Guo, IrynaBalagura, Ivan Gorbov & Hongbo Yang. Link prediction of scientific collaboration networks based on informationretrieval // World Wide Web : Internet and Web Information Systems. — N 23, pp. 2239-2257(2020). DOI:doi.org/10.1007/s11280-019-00768-9. ISSN: 1573-1413, 1386-145X.
8.Dmytro Lande, Oleh Dmytrenko, Oksana Radziievska. Determining the Directions of Links in Undirected Networks of Terms // Selected Papers of the XIX International Scientific and Practical Conference «Information Technologies and Security» (ITS 2019). CEUR Workshop Proceedings (ceur-ws.org). — Vol-2577. — pp 132-145 ISSN 1613-0073.
9.Minglei Fu, Jun Fenga, Dmytro Lande, Oleh Dmytrenk, Dmytro Mankob, Ryhor Prakapovich. Dynamic model with super spreaders and lurker users for preferential information propagation analysis // (2020) Physica A: Statistical Mechanics and its Applications.Volume 561, 1 January 2021, 125266, DOI: doi.org/10.1016/j.physa.2020.125266.
Страница находится на стадии доработки